In this blog post… —> ToDo
Hier gehts Weiter mit ToDo
Blogbeitrag b.telligent: Databricks Cost Saving Tipps
[TOC]
Admin
Rest-Budget: 3h
ToDo
- Delta Live Tables, AI / BI erwähnen, DataVault -> Modellierung
- Gegenlesen
- Sven Kühne
- Marco Amhof
- Auch auf eigenem Blog veröffentlichen und auch auf MEdium
Titel
Das BI-Paradox mit der Databricks Data Intelligence Platform: einfacher, smarter, günstiger
Ideen
- DBU beschreiben: was ist das, wie ist es aufgebaut, etc.
- Call your databricks Sales —> get better prices
- Allg. Databricks ressourcen verwenden anstatt 3rd Party
Monitoring: System-Tables abfragen
Inhalte von folgendem Artikel nehmen:
https://www.chaosgenius.io/blog/databricks-optimization-techniques/
Hat b.telligent einen Account auf Medium?
https://medium.com/@matt_weingarten/databricks-cost-saving-tips-48ffe2d3b160
https://medium.com/@mariusz_kujawski/databricks-cost-optimizations-e4c0f1670c5b
- Databricks Unit pre-purchase plans: https://learn.microsoft.com/en-us/azure/cost-management-billing/reservations/prepay-databricks-reserved-capacity
https://www.tarento.com/articles/how-to-optimize-costs-in-databricks/
https://overcast.blog/databricks-cost-optimization-a-practical-guide-d609a9cee9ec
https://www.finout.io/blog/optimize-databricks-costs
https://dataforest.ai/blog/databricks-reduce-the-cost-of-big-data
https://www.ikidata.fi/post/databricks-cost-optimization
https://becominghuman.ai/how-we-saved-60-of-our-monthly-azure-databricks-cost-dbbbcdfd54e6
https://www.cloudzero.com/blog/databricks-pricing/
https://www.sunnydata.ai/blog/cost-saving-best-practices-for-databricks-workflows
https://www.analytics8.com/blog/guide-to-optimize-databricks-for-cost-and-performance/
https://bpcs.com/blog/6-quick-wins-for-databricks-cloud-cost-optimization
https://wtdanalytics.com/blog/maximizing-databricks-cost-efficient-data-platform
https://www.vertice.one/blog/databricks-pricing-your-discount-options
https://dataengineeringcentral.substack.com/p/cost-savings-for-databricks-users
Fabric Prizing:
Teaser
Anleitung: Hier bitte einen kurzen, informativen Text einfügen, 2-3 Sätze, der Lust auf den Inhalt des Blogbeitrags macht.
Also, was erfahren die Lesenden spannendes, wenn sie denn Blogbeitrag lesen. Dieser Text erscheint in der Übersichtsansicht unter dem Titel, nicht im Blogbeitrag selbst.
—> am besten am Schluss machen, wenn der Beitrag steht!
Ideen:
- Warum kostet Ihr BI-System mehr, je schlechter es wird?
- Wieso muss man hohe initiale Kosten initiale
- Sie stehen vor der Aufgabe, ihr BI-System zu migrieren?
- Falls Sie sich diese oder ähnliche Fragen stellen,……
Kurzfassung / Lead
Anleitung: In dieser Kurzfassung bzw. „Lead“, bitte von der Überschrift zum Bloginhalt überleiten. Hier soll in 250 Zeichen dargestellt werden, WAS im Blogbeitrag erläutert wird und WELCHES der Mehrwert für die Leser ist.
—> am besten am Schluss machen, wenn der Beitrag steht!
Einleitung
- Darauf Eingehen, dass man mit Databricks sehr kosteneffektive Architekturen bauen kann, aber auch die schwersten Workloads bewältigt
- und das bei der selben Architektur
Was ist ein BI-System?
Ein BI-System unterstützt ein Unternehmen dabei, Daten zu analysieren und daraus wertvolle Erkenntnisse für fundierte Entscheidungen zu gewinnen. Es kombiniert Technologien, Prozesse und Tools, um Daten aus verschiedenen Quellen zu sammeln, zu integrieren, zu analysieren und zu visualisieren.
Ein BI-System besteht aus zwei zentralen Komponenten: dem Backend und dem Frontend. Im Backend werden die Daten gespeichert, verarbeitet und für die Analyse vorbereitet.
Das Frontend umfasst eine oder mehrere BI-Software, die den Zugriff auf diese Daten ermöglicht und Werkzeuge für Analyse, Berichterstellung und Visualisierung bereitstellt.
Traditionellerweise wird im Backend ein Data Warehouse (DWH) verwendet. Das Konzept des Data Warehouse (DWH) existiert bereits seit den 1980er-Jahren. Zusätzlich zu einem Data Warehouse wurden ab den frühen 2010er-Jahren Data Lakes populär, insbesondere mit der wachsenden Bedeutung von Big Data und der Einführung verteilter Technologien wie Hadoop und später Apache Spark.
Die Herausforderungen mit traditionellen BI-Systemen
Traditionelle BI-Systeme stossen zunehmend an ihre Grenzen. Sie verursachen hohe Kosten, bieten jedoch oft nur langsame Berichte, geringe Flexibilität und eingeschränkte Analysefähigkeiten. Daten werden über verschiedene Systeme verteilt, was Zusammenarbeit erschwert und Entscheidungen auf fragmentierter Basis erzwingt. Die starren Architekturen dieser Systeme sind schwer anpassbar und reagieren schlecht auf neue Anforderungen oder wachsende Datenmengen.
Oft wird eine Kombination von verschiedenen Technologien eingesetzt, mehrere Tools und Plattformen für Speicherung, Datenintegration, Analyse und Visualisierung. Dies führt häufig zu Herausforderungen wie erhöhtem Verwaltungsaufwand, komplexen Schnittstellen, Dateninkonsistenzen und einer erschwerten Koordination zwischen den Systemen.
Veraltete ETL-Prozesse und Batch-orientierte Verarbeitung führen zu Verzögerungen, während Echtzeitdaten und fortschrittliche Analysen wie Predictive Analytics fehlen. Außerdem erfordern viele Prozesse manuellen Aufwand, erhöhen die Fehleranfälligkeit und binden Ressourcen. Die fehlende Integration moderner Technologien wie KI, maschinellem Lernen oder Cloud-Lösungen verhindert, dass Unternehmen das Potenzial ihrer Daten voll ausschöpfen.
Insgesamt sind traditionelle BI-Systeme für die Anforderungen moderner, datengetriebener Unternehmen nicht mehr vollends geeignet.
Kostentreiber in der BI
Weitere Kostentreiber:
•Datenmenge
•Transformationslogik
•Realtime vs. Batch
•Netzwerk-Architektur (Public vs. Private Endpoints)
•Standort Rechencenter
•ELT-Framework (Lizenzen, Entwicklungskosten, Automatisierung,…)
•Zugriff Endbenutzer: Anzahl Nutzer, Latenz Datenabfrage
Welche Faktoren treiben die Kosten in einem BI-Projekt in die Höhe? Grundsätzlich sind es diesselben oder ähnliche Faktoren, wie sie auch in anderen IT-Projekten vorkommen. Diese kann in man in 3 Hauptkategorien einteilen:
- Hardware- und Infrastruktur-Kosten
- Lizenz-Kosten
- Personal-Kosten
Hardware- und Infrastrukturkosten
Diese Kategorie umfasst alle Ausgaben, die mit der technischen Basis des BI-Systems verbunden sind. Dazu zählen physische Server und Speichersysteme, die für die Speicherung und Verarbeitung von Daten benötigt werden, sowie die Netzwerkinfrastruktur, die den Datenfluss zwischen verschiedenen Systemen sicherstellt. In modernen BI-Architekturen spielen auch Cloud-Dienste eine zentrale Rolle, bei denen Gebühren für Speicherplatz, Rechenleistung und Datenübertragung anfallen. Zusätzlich verursachen der Betrieb und die Wartung dieser Infrastruktur – wie Monitoring, Updates und die Behebung von Ausfällen – laufende Kosten, die langfristig ins Gewicht fallen.
Lizenzkosten
Lizenzen stellen einen weiteren großen Kostenblock dar, da BI-Tools und unterstützende Software meist kostenpflichtig sind. Dazu zählen Analyseplattformen wie Power BI, Tableau oder Qlik sowie Datenintegrationswerkzeuge wie Informatica oder Talend. Oft werden diese Softwarelösungen als Abonnement angeboten, bei dem die Kosten von der Anzahl der Benutzer oder der genutzten Kapazität abhängen. Darüber hinaus fallen Lizenzgebühren für Datenbanken an, ob es sich nun um relationale Systeme wie SQL Server oder spezialisierte Lösungen für Big Data handelt. Zusätzliche Funktionen wie maschinelles Lernen oder API-Nutzung können die Lizenzkosten weiter erhöhen.
Personalkosten
Personalkosten machen einen erheblichen Anteil der Gesamtkosten in BI-Projekten aus, da die Entwicklung und der Betrieb von BI-Systemen hochqualifizierte Fachkräfte erfordern. Data Engineers, Data Scientists und BI-Entwickler sind unverzichtbar für die Integration, Modellierung und Analyse von Daten. Auch die IT-Abteilung spielt eine wichtige Rolle, insbesondere bei der Verwaltung der Infrastruktur und der Sicherstellung eines reibungslosen Betriebs. Externe Berater werden häufig hinzugezogen, um spezifische Expertise oder zusätzliche Ressourcen bereitzustellen, was ebenfalls kostspielig sein kann. Schließlich sind Schulungen erforderlich, um sicherzustellen, dass Mitarbeitende die eingesetzten BI-Tools effektiv nutzen können.
Das Grundrezept, um also die Kosten zu senken, besteht darin, die vorhandene Hardware und Infrastruktur effizienter zu nutzen, Lizensierungskosten optimaler zu gestalten und Personalkosten zu senken.
Nachfolgend gebe ich Ihnen verschiedene Tipps, wie sie mit Databricks die Kosten in ihrem BI-Projekt senken können.
Das Geschäftsmodell von Databricks
Databricks hat ein Konsumption modell…
Die Kosten können mit dem Databricks DBU-Calculator berechnet werden:
https://www.databricks.com/product/pricing/product-pricing/instance-types
Das ist natürlich nur die eine Seite vom Kuchen, denn es fallen noch Hardware-Kosten an. Für dies muss man natürlich auch die Kosten berechnen:
ToDo: KOstenrechner der jeweiligen Cloud-Provider hinterlegen.
Tipps
nachfolgend haben wir die wichtigsten Tipps zusammengefasst.
Das Offensichtliche
Architektur Tipps
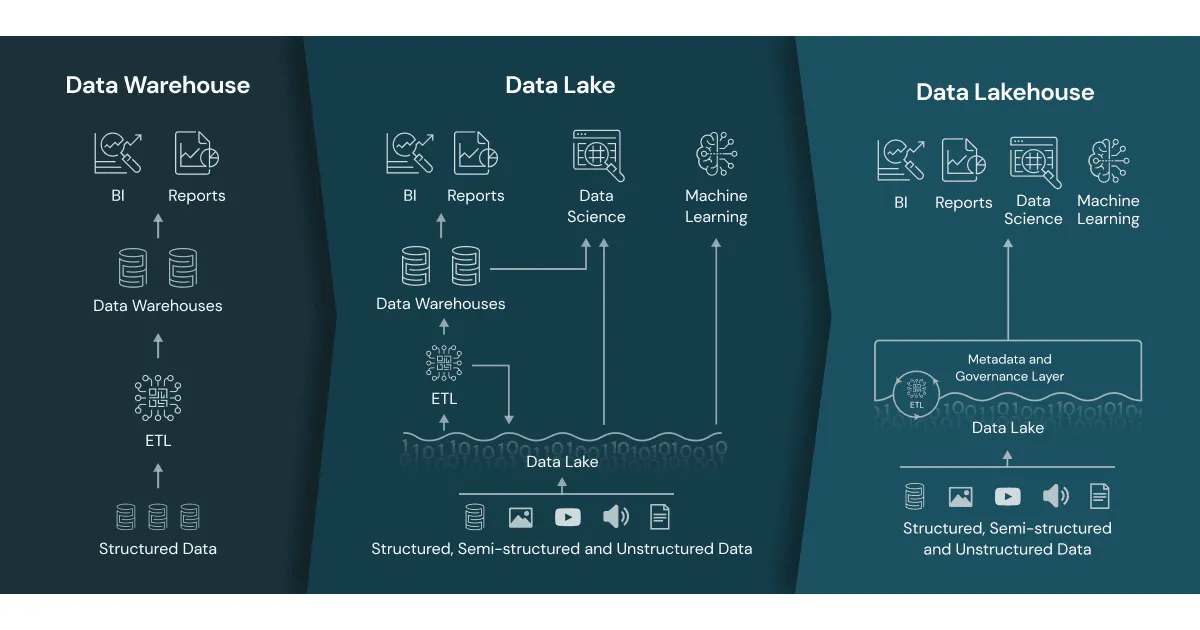
Glückwunsch, wenn Sie diesen Artikel lesen, dann haben Sie schon ein Lakehouse im Einsatz. Aber was bedeutet das genau?
Trennung von Compute & Storage
Im Januar 2020 veröffentlichte Databricks die Vision des Lakehouses auf ihrer Webseite.
https://www.databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.htm
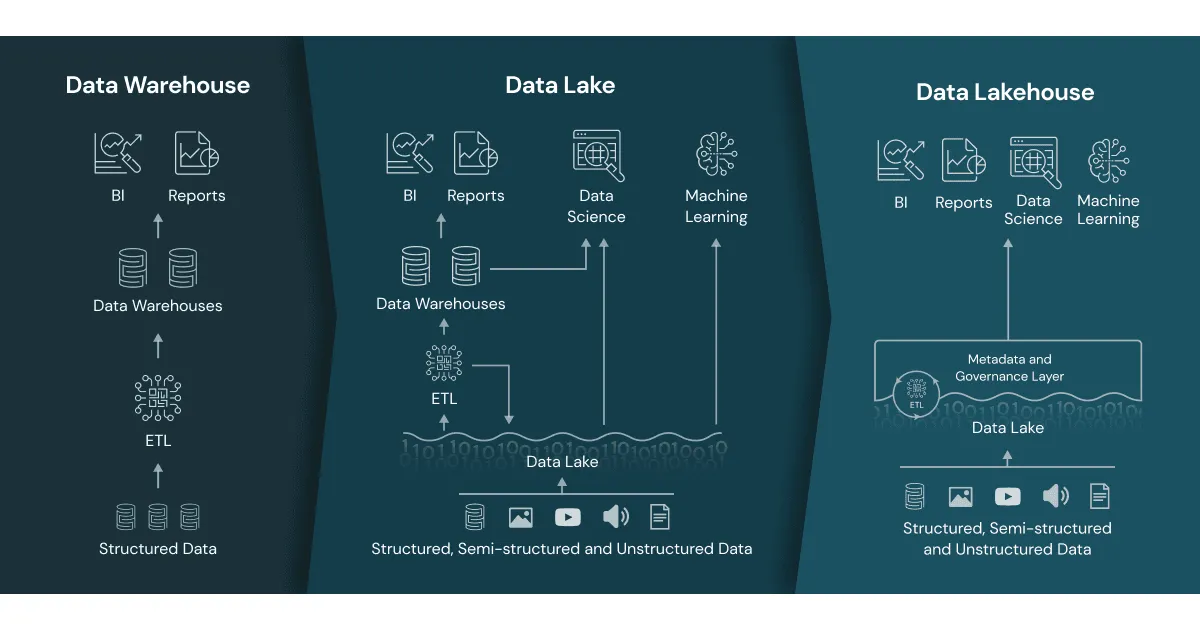
Quelle Bild: https://www.databricks.com/wp-content/uploads/2020/01/data-lakehouse-new.png
{kind=link}
Bei diesem Paradigma geht es darum die Vorteile von Data Lakes und Data Warehouses zu vereinen. Eine neue Art der Datenmanagement-Architektur, die die Flexibilität und Kosteneffizienz von Data Lakes mit den Datenverwaltungsfunktionen und ACID-Transaktionen von Data Warehouses kombiniert. Dies ermöglicht sowohl Business Intelligence (BI) als auch Machine Learning (ML) auf allen Daten innerhalb einer einzigen Plattform.
Heute, rund 5 Jahre später ist dieses Konzept nicht mehr wegzudenken.
Durch die Trennung von Compute und Storage kann man sehr grosse Datenmengen auf einem günstigen Speicher wie einem Data Lake halten. Für die Verarbeitung der Daten wird das Compute bei Bedarf hochgefahren, und anschliessend wieder heruntergefahren. Da Databricks eine Cloud-Datenplattform ist, kann man die Vorteile der Cloud hier voll ausnutzen: „Pay Per Use“. Man bezahlt effektiv nur das, was man auch verbraucht.
Ein Wechsel auf ein Lakehouse kann schon
-Konsequent auch Lakehouse Paradigma einsetzen,nicht mixen
Data Lake Design
- Den Data Lake Entsprechend designen? Archive einplanen, Backup, Partitionierung
- Hot- und Cold-Storage benutzen
Benutzen Sie Databricks Workflows
Anstatt Data Factory
-weniger Komplexität & Kosten
Allgemeine Tipps
Reduzierung Technologie-Mix
Automatisierung
Tipps zu Speicher
Wahl des Datei Formates
In jedem BI-Projekt müssen auch Rohdaten gespeichert werden. Dabei kann man schon grosse Kosten sparen, indem das geeignete Dateiformat gewählt wird. Vermeiden sollte man CSV oder …
- Am besten eignet sich sich natürlich das Delta Format
Tipps zu Compute
Wahl des geeigneten Clusters
Cluster ist nicht gleich Cluster, da gibt es markante Unterschiede sowohl in der Leitung wie auch im Pricing? Die Kunst bei der Wahl des Clusters liegt darin eine ausgewogene Mischung an Kosten und Leistung zu wählen. Die erste Frage stellt sich dabei, ob Serverless- oder Klassisches Compute gewählt wird.
- Serverless oder Classic Compute?
- Job Compute
- Warehouse Workloads:
- Developping
- GPU nur in Machine-Learning
Die Wahl des geeigneten Worker-Types (VM)
Die physikalische VM, welche dem Worker zugrunde liegt.
Allg. kann gesagt werden, Faustregel: je neuer, um so besser Performance, aber:
—> erwähnen, dass wir bei EWZ verschiedne Tests durchgeführt haben und da auf ganz andere Ergebnisse gestossen sind
Zum Sortieren
Databricks Runtime
Auto-Scaling
Private vs. Public Endpoint
Photon oder nicht
Die richtige Region wählen
- In Azure (oder auch AWS, GCP) zahlt man nicht in jeder Region denselben Preis. Das heisst, die Preise sind unterschiedlich für die Services / Hardware
• ⁃ Je nach Region sind gewisse Featire von Databricks nicht verfügbar —> so ist man ebenfalls eingeschränkt
Monitor Resource usage
Implement monitoring and alerting systems to track resource consumption. Identifying performance bottlenecks and resource constraints is essential for optimization.
Policies
- Sie möchten nicht, dass Jemand aus Versehen einen Cluster aus Versehen hochfährt, welcher 3000 CPU-Kerne und 5 TB RAM hat…..
- Personal Compute: Avoid Standard-Einstellungen
• ⁃ 4320 Minuten = 72 Stunden = 3 Tage
schreiben Sie effektiven Code
Leichter gesagt als getan 😉
Beispiel von Pilatus mit Falsch formatiertem JSon File. — anruf beim Hersteller und schon erledigt
Aber z.B. Best 0ractices Spark einsetzen, nicht sortieren, etc.
Streaming vs. Batch
Vergleich von verschiedenen Konfigurationen
Sie sind nicht sicher, welche Cluster-Konfiguration die Beste ist? Dann bietet es sich an, Vergleiche durchzuführen.
Verzichten auf Lizenz-Fallen
Conclusion & Call to Action
Sie sind nicht sicher, ob sie zuviele Kosten ausgeben? Sie möchten gerne Ihre Plattform einem Review unterziehen? Lassen Sie Ihre Plattform durch unsere Experten beleuchten.
Additional Links
Databricks DBU-Calculator:
https://www.databricks.com/product/pricing/product-pricing/instance-types
Databricks Doku: Best practices for cost optimization
https://docs.databricks.com/en/lakehouse-architecture/cost-optimization/best-practices.html
Related Articles
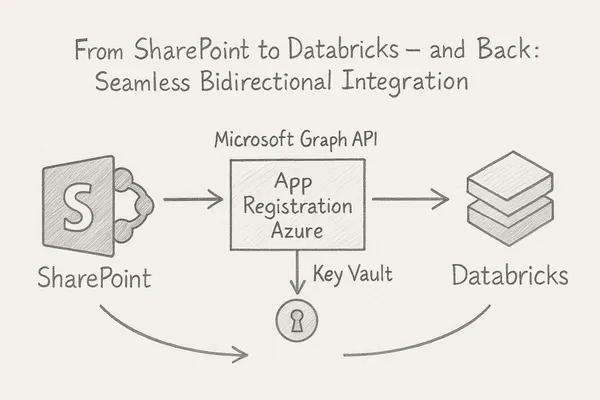
From SharePoint to Databricks – and Back: Seamless Bidirectional Integration
In modern data workflows, it’s essential to collect data where it originates and deliver it to where it’s needed. In this blog post, I’ll show how to connect **SharePoint directly with Databricks** –
From Snapshots to CDC: How to load Snapshot-Data with Databricks Delta Live Tables
In this article I describe how to load data from recurring full snapshots with Delta Live Tables relatively easily and elegantly into a bronze table without the amount of data exploding.

MS SQL Server Meets Lakehouse: Integrating Databricks SQL Warehouse as a Linked Server
In this blog post, I explore how to set up Databricks SQL Warehouse as a Linked Server in MS SQL Server to seamlessly query data from your Lakehouse directly within SQL Server.
Comments
Comments are powered by giscus. You need a GitHub account to comment.