In modern data workflows, it’s essential to collect data where it originates and deliver it to where it’s needed. In this blog post, I’ll show how to connect SharePoint directly with Databricks – in both directions.
Introduction
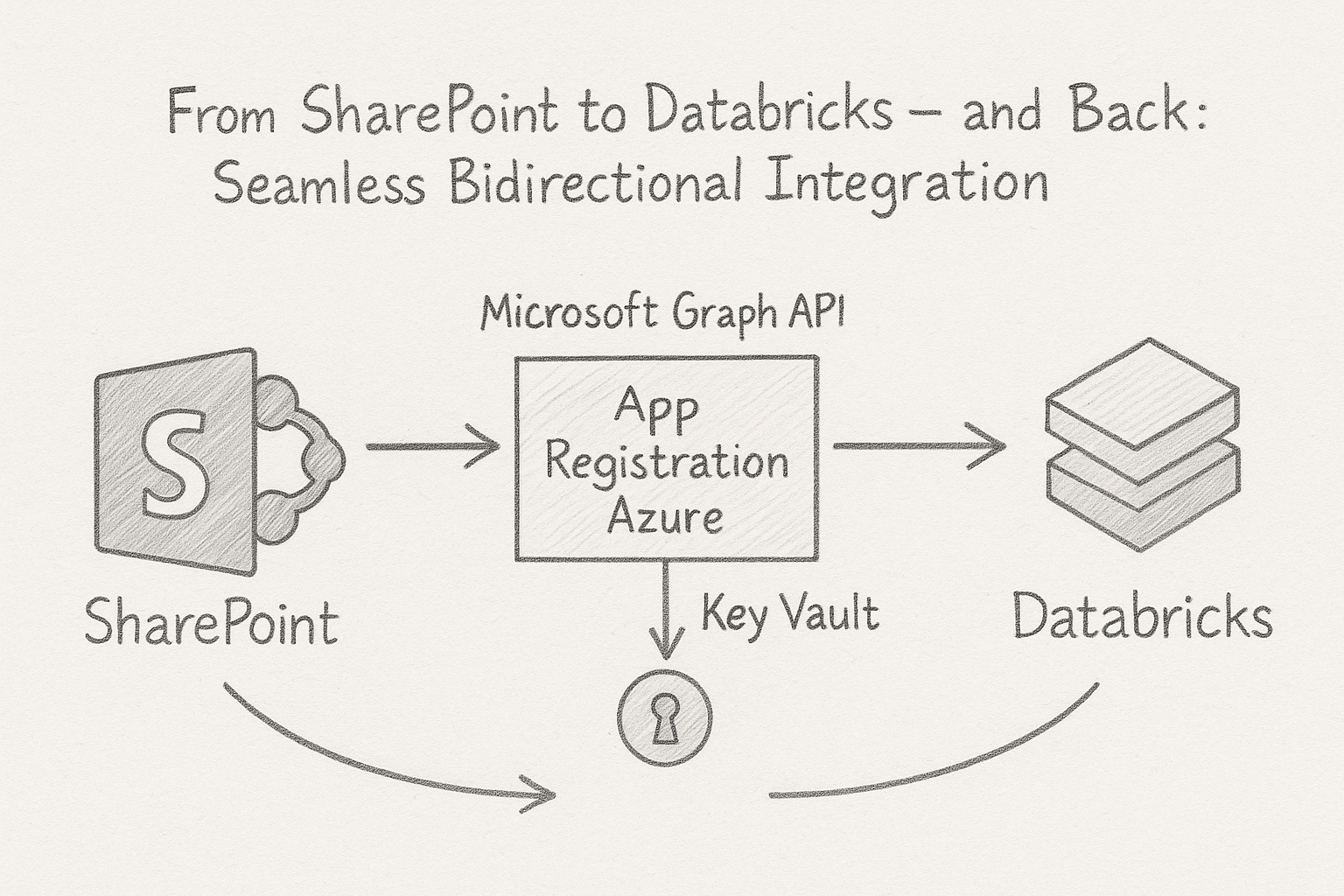
Many companies still rely on Azure Data Factory or Logic Apps to extract SharePoint files into a Data Lake before processing them in Databricks. While this approach works, it comes with trade-offs: the architecture becomes more complex, latency increases, any change in the SharePoint structure may break pipelines, and writing data back to SharePoint often requires additional components or workarounds. A direct integration using the Microsoft Graph API is not only more elegant – it’s also faster, more flexible, and easier to maintain.
This means I can read structured files, such as Excel or CSV, directly from SharePoint into Databricks – without the need for mapped drives or manual exports. Just as easily, I can write results from Databricks – such as aggregated reports or machine learning outputs – back to SharePoint, where they are instantly available to business users or downstream systems.
This turns SharePoint from a static input source into a fully integrated part of a data-driven workflow on the Databricks Lakehouse platform.
To allow Databricks to access SharePoint, I use an App Registration in Azure – a Service Principal that authenticates against the Microsoft Graph API. This app is granted the necessary permissions (e.g., Sites.ReadWrite.All) to read and write files in SharePoint. Access is handled via an access token used within my Databricks notebooks, with no need for interactive logins or manual approvals. This creates a secure and fully automated connection between Databricks and SharePoint.
Creating an App Registration in Azure
Go to the Azure Portal and navigate to App Registration. Click New registration.
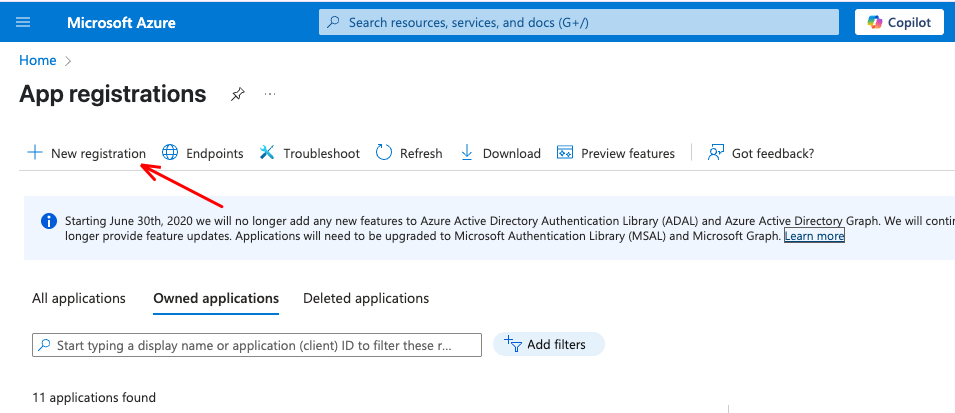
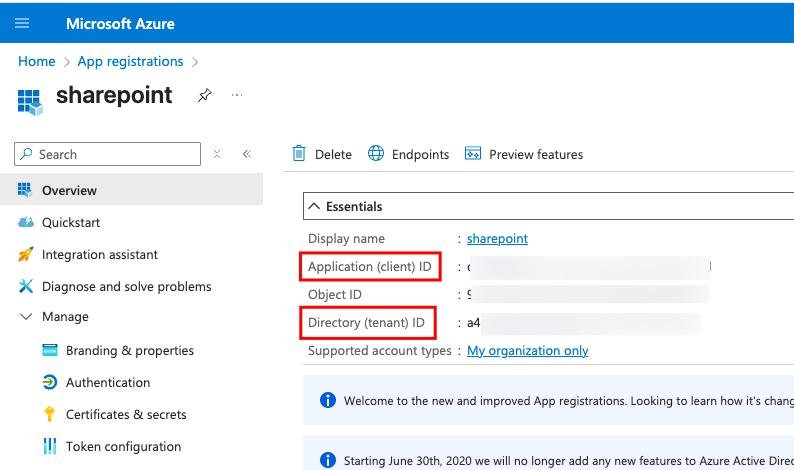
Choose a name (e.g., databricks-sharepoint-access) and keep the default setting for single-tenant access. In my example i called it “sharepoint”. Copy the Application (client) ID and the Directory (tenant) ID to a safe place.
Then, create a new secret.
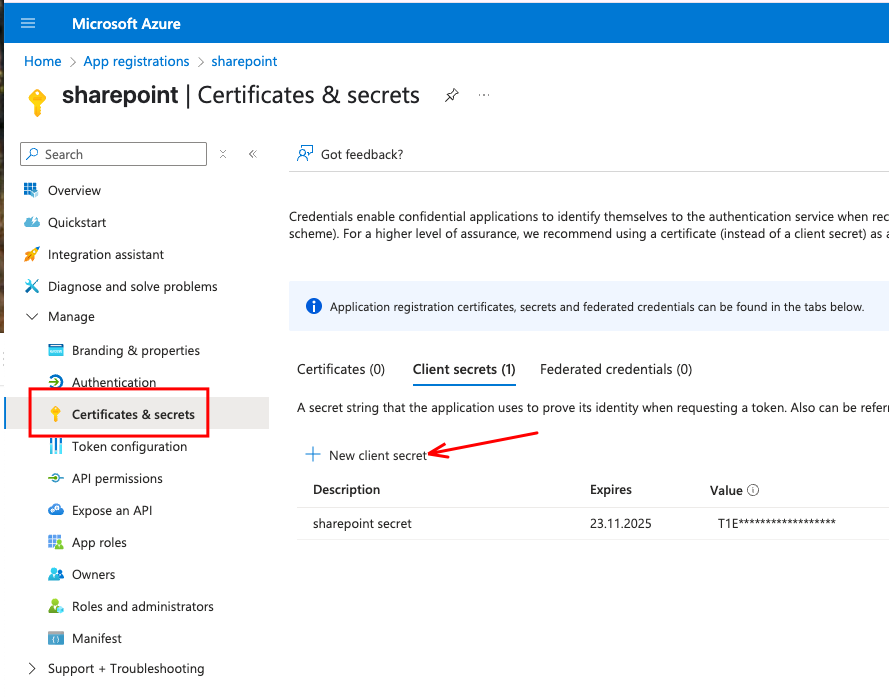
After the secret is created, copy the value to a safe place. You only see the secret once.
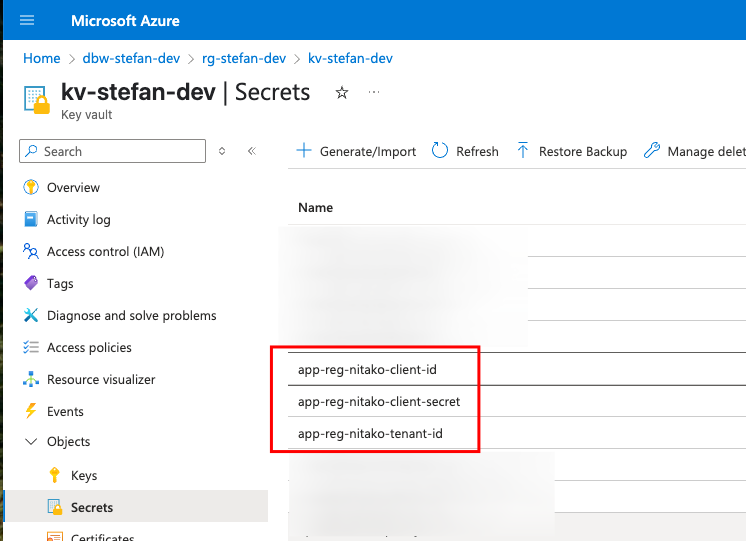
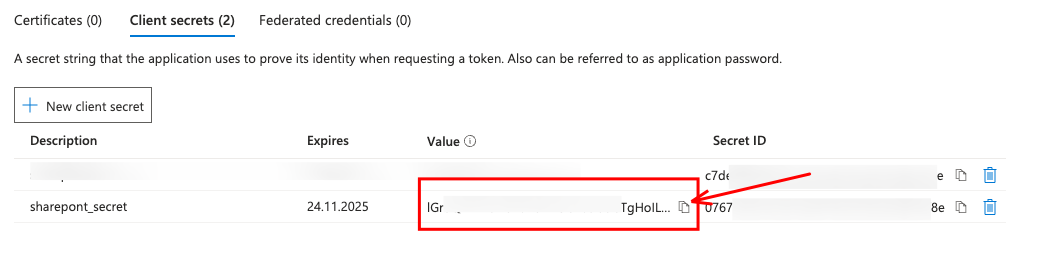 The safe place for Secrets in Azure is a KeyVault. So, I save the three secrets for the App registration in the Key Vault.
The safe place for Secrets in Azure is a KeyVault. So, I save the three secrets for the App registration in the Key Vault.
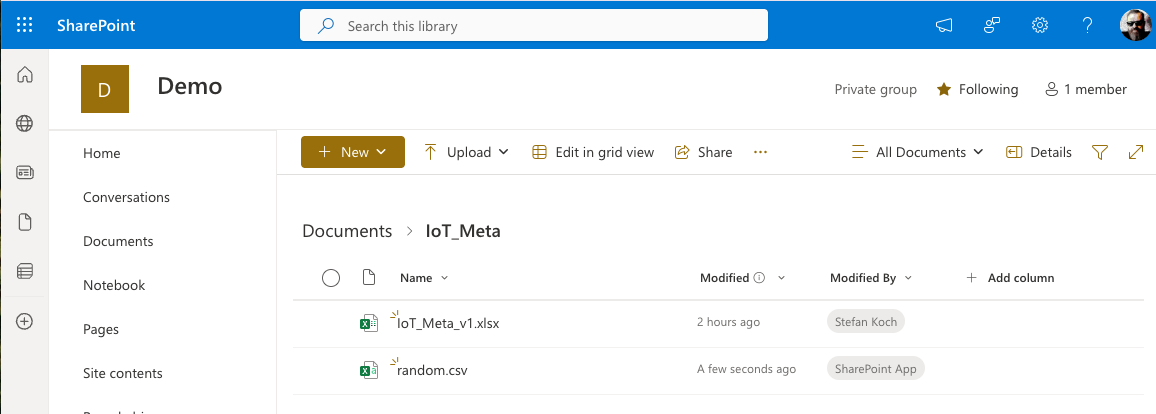
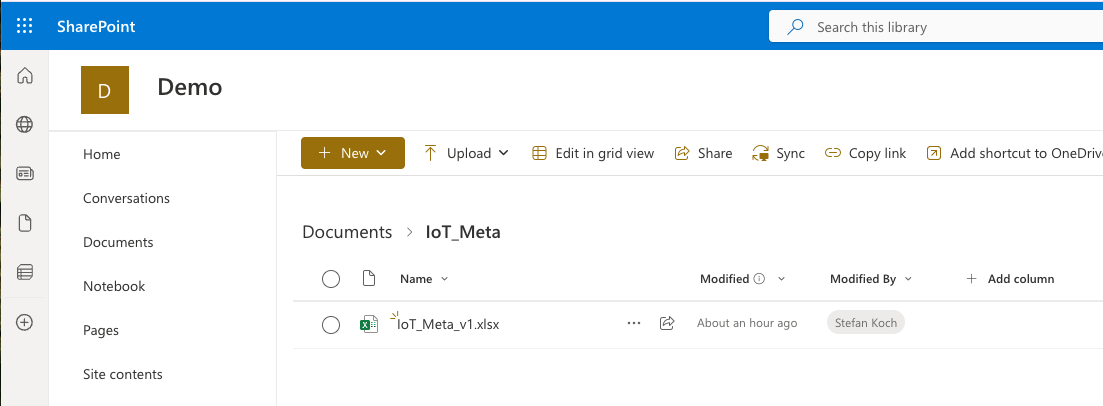
The Sharepoint Folder
In my example, I created a new SharePoint site named Demo. Inside the Documents Section, I made a folder IoT_Meta and uploaded an Excel file.
Grant Permission on SharePoint to the App Registration
To read and write to the SharePoint folder, we need to grant the proper permissions to the App Registration. For this, you set the Permissions on the App Registration. On the App registration, go to API Permissions. For Microsoft Graph, I set the following permissions:
- Files.Read.All
- Files.ReadWrite.All
- Sites.ReadWrite.All
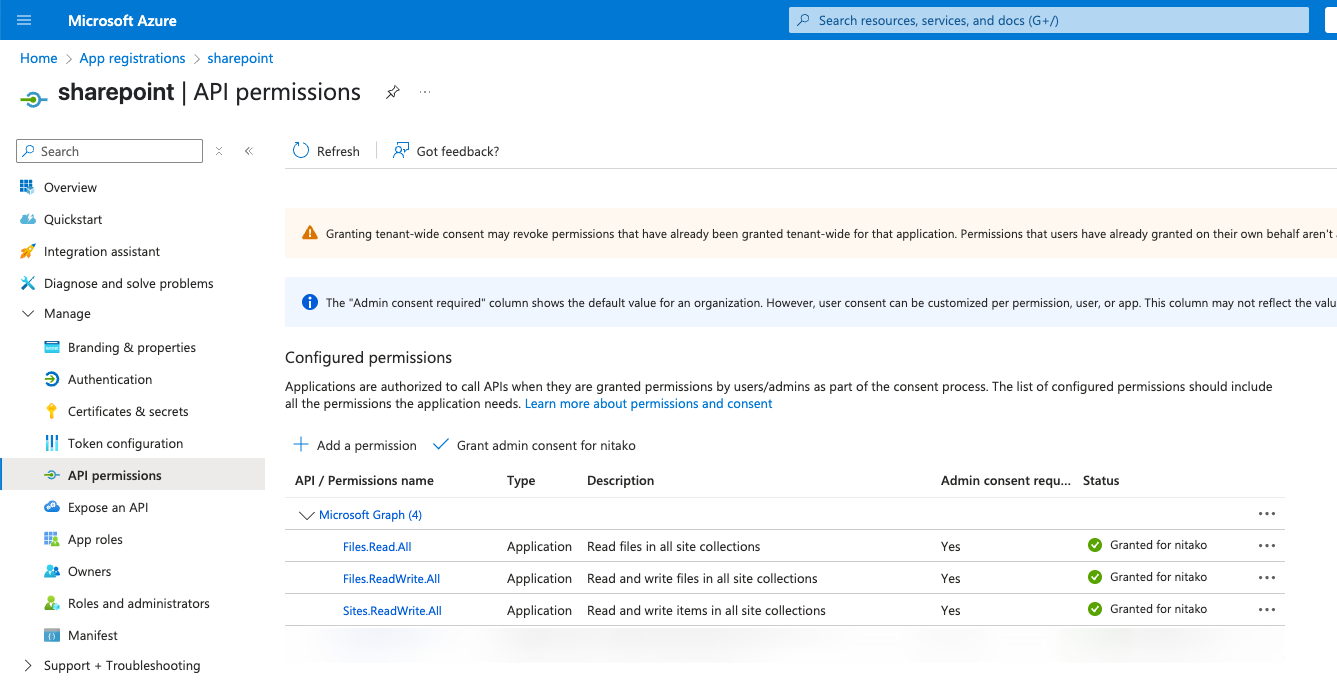
Of course, these permissions have to be clarified with your SharePoint Administrator.
Then I have to set the permissions on the SharePoint site. For this, open the following URL in your web browser:
|
|
Replace <YOUR_TENANT> and <YOUR_SITE> with your values.
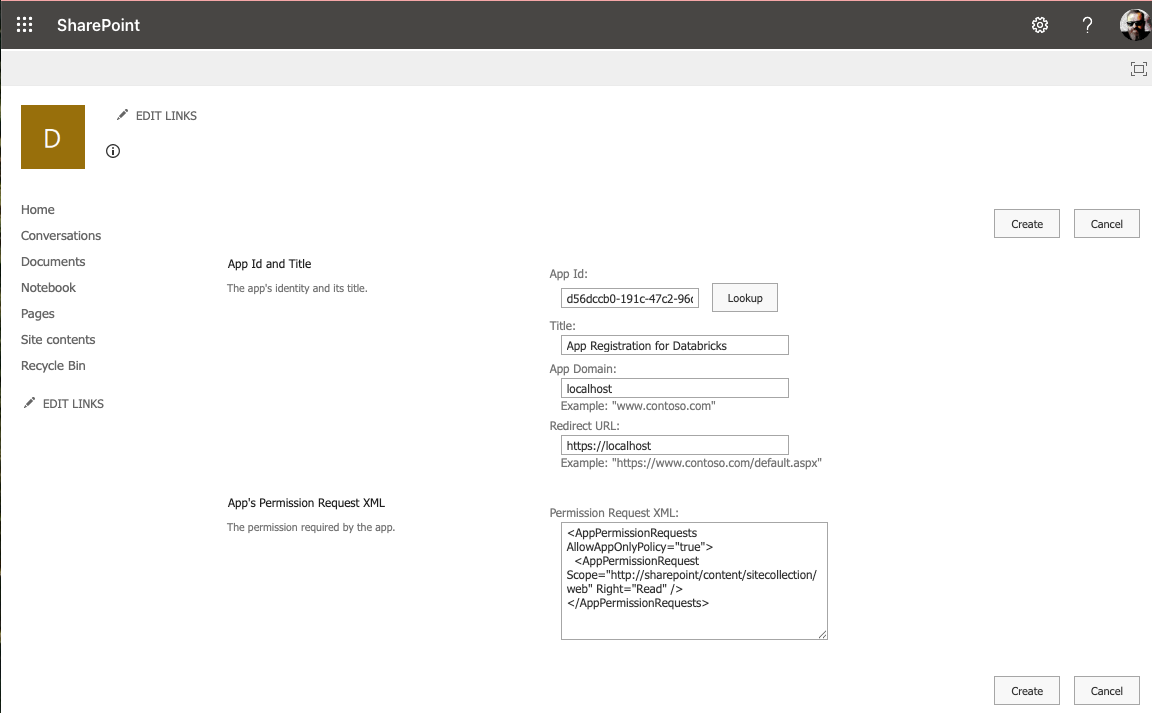
Fill in the needed Information in the fields:
App Id: Application Id from your App registration
Title: Whatever Title you want
App Domain: localhost
Redirect URL: https://localhost
Permission Request XML: You can choose read or write:
Read:
|
|
Write:
|
|
Databricks Preparation
In Databricks, you can implement your code. The following code is for demo purposes only. In production, you should improve it with error handling, parameters, and so on.
We will retrieve the files using the Python requests method, so that I will import the library and some other necessary libraries as well.
|
|
Set the secrets from the key vault.
|
|
Create an access token.
|
|
Create the request’s header and get the site ID from the SharePoint site.
|
|
Read from Sharepoint
Get the Excel file from SharePoint. As this is just an example, the path and file are hardcoded; however, you can make this code more generic.
|
|
I get a message when the code finishes run:
|
|
Have a look at the destination folder. Now we have the file in a Databricks Unity Catalog Volume.
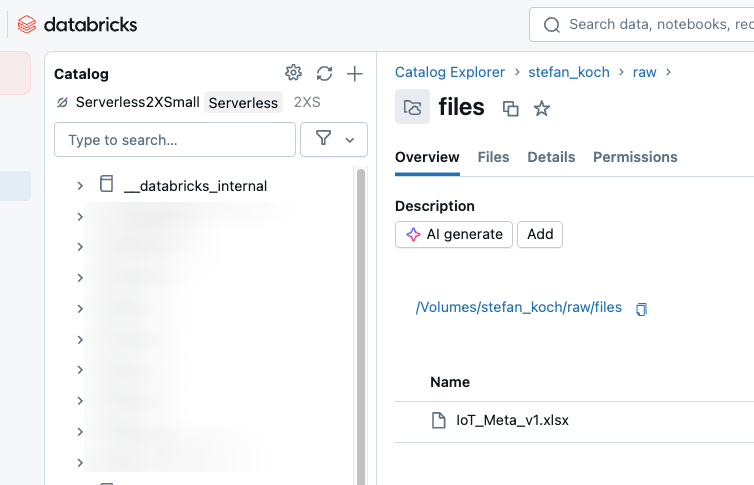
Here we can start additional pipelines to read the content from the Excel file.
Write to Sharepoint
In the following example, I want to write to SharePoint from Databricks. To achieve this, I generate some random data and store it in a dataframe.
|
|
Now, save the CSV file on SharePoint.
|
|
Refresh your SharePoint site, and you will see the newly created file.